拳打 Pika 脚踢 Gen-2!斯坦福李飞飞联合谷歌,AI 文生视频大模型炸圈
智东西(公众号:zhidxcom)
作者 | 李水青
编辑 | 漠影
AI 文生视频赛道正呈现出爆发之势!
继本月 AI 文生视频工具 Pika 1.0 爆火出圈、Gen-2 效果大升级之后,斯坦福大学 AI 科学家李飞飞的团队也有了新动作!
智东西 12 月 12 日报道,今日,李飞飞及其学生团队与谷歌合作,推出了 AI 视频生成模型 W.A.L.T(窗口注意力潜在 Transformer ,Window Attention Latent Transformer)。
▲李飞飞在社交平台 X 发声转发
演示中,W.A.L.T 可以通过自然语言提示,生成 3 秒长的每秒 8 帧、分辨率达 512 × 896 的逼真视频。

▲ W.A.L.T 的文生视频示例
W.A.L.T 可以让一张静态图片变为一个的动态感十足的动图。

▲ W.A.L.T 的图生视频示例
W.A.L.T 还可以用于生成 3D 摄像机运动的视觉效果。

▲ W.A.L.T 的 3D 视频生成示例
与爆火的 Pika 1.0、Gen-2 等同类工具类似,W.A.L.T 采用扩散模型(Diffusion Model)技术。
同时,W.A.L.T 的创新之处在于,其将 Transformer 架构与潜在扩散模型(Latent Diffusion Models,LDM)相结合,在一个共享潜在空间中压缩图像和视频,从而降低计算要求,提高训练效率。
根据论文,W.A.L.T 在视频生成基准 UCF-101 和 Kinetics-600、图像生成基准 ImageNet 测试上实现了 SOTA(当前最优效果)。
项目地址:
https://walt-video-diffusion.github.io/
论文地址:
https://walt-video-diffusion.github.io/assets/W.A.L.T.pdf

▲ W.A.L.T 相关论文截图
一、一句话生成 3s 视频,高逼真、强动态、3D 视觉
W.A.L.T 模型目前支持文生视频、图片转视频和 3D 相机拍摄视频三项能力,团队展示了一系列 W.A.L.T 生成示例。
1、文生视频:一句话生成高清逼真视频
输入一句简短的提示词,W.A.L.T 模型就可以给出一个 3 秒长的逼真视频。以下是一些示例:
阳光明媚的下午,宇航员在喂鸭子。(An astronaut feeding ducks on a sunny afternoon.)

一头戴着生日帽的大象在海滩上行走。(An elephant wearing a birthday hat walking on the beach.)

皮卡丘在拳击场内戴着拳击手套。(Pikachu wearing boxing gloves, inside a boxing ring.)

一只可爱的熊猫在天空中滑板,越过雪山,充满梦幻和异想天开的气氛。(A cute panda skateboarding in the sky, over snow covered mountains, with a dreamy and whimsical atmosphere.)

一对情侣撑着雨伞走回家,倾盆大雨,油画风格。(A couple walking home with umbrellas, heavy downpour, oil painting style.)

2、图片转视频:用户提供图片,生成动态视频
这里的图片不是由 W.A.L.T 模型生成的,但动态效果是的,如下面的示例所示:
一个穿着全套太空服的宇航员骑着马,慢动作。(An astronaut in full space suit riding a horse, slow motion.)

一个巨大的机器人在雪里行走。(A giant robot walking through a snowy landscape.)

一只大泰迪熊慢镜头走在第五大道上。(A large teddy bear walking down 5th avenue, slow motion.)

3、3D 相机拍摄视频:物体全景多细节展示
团队还展示了 3D 视频内容的生成,效果看起来就像一个 3D 摄像机拍摄而来。示例如下:
镜头转向盘子里的汉堡,工作室。(Camera turns around a burger on a plate, studio lighting, 360 rotation.)

摄像机绕着戴着一副耳机的南瓜,工作室灯光,360 度旋转。(Camera turns around a pair of headphones around a pumpkin, studio lighting, 360 rotation.)

二、Transformer+ 潜在扩散模型,降低计算成本
Transformer 在处理视频等高维数据时成本过高,潜在扩散模型(Latent diffusion models,LDM)可以降低计算要求。
因此,李飞飞学生团队与谷歌研发者共同提出了窗口注意力潜在 Transformer(Window Attention Latent Transformer,W.A.L.T),这是一种基于 Transformer 的潜在视频扩散模型(latent video diffusion models,LVDM)方法。
当下,市面上的同类工具如 Pika Labs 推出的 Pika 1.0、Runway 的 Gen-2,大都采用扩散模型(Diffusion Model),这是很长时间里图像和视频生成领域的主流技术路线。
W.A.L.T 沿用这一主流技术路径,并在此基础上进行创新,主要实现以下两方面的升级:
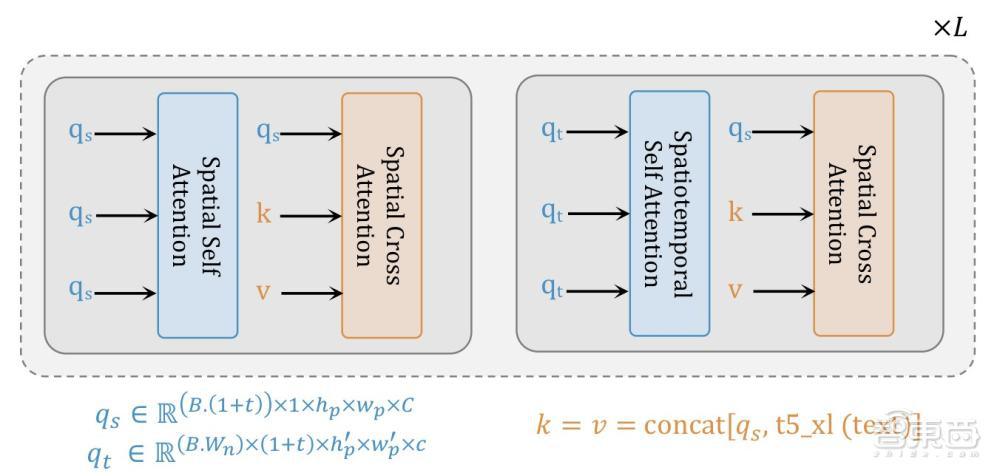
1、使用局部窗口注意力,显著降低计算需求。
2、更有利的联合训练:空间层独立处理图像和视频帧,而时空层专注于时间关系建模。
据悉,这一架构主要的优势是它能同时在图像和视频数据集上进行训练。
这得益于 W.A.L.T 的两个关键决策:
1、使用因果编码器,在一个共享潜在空间中压缩图像和视频。
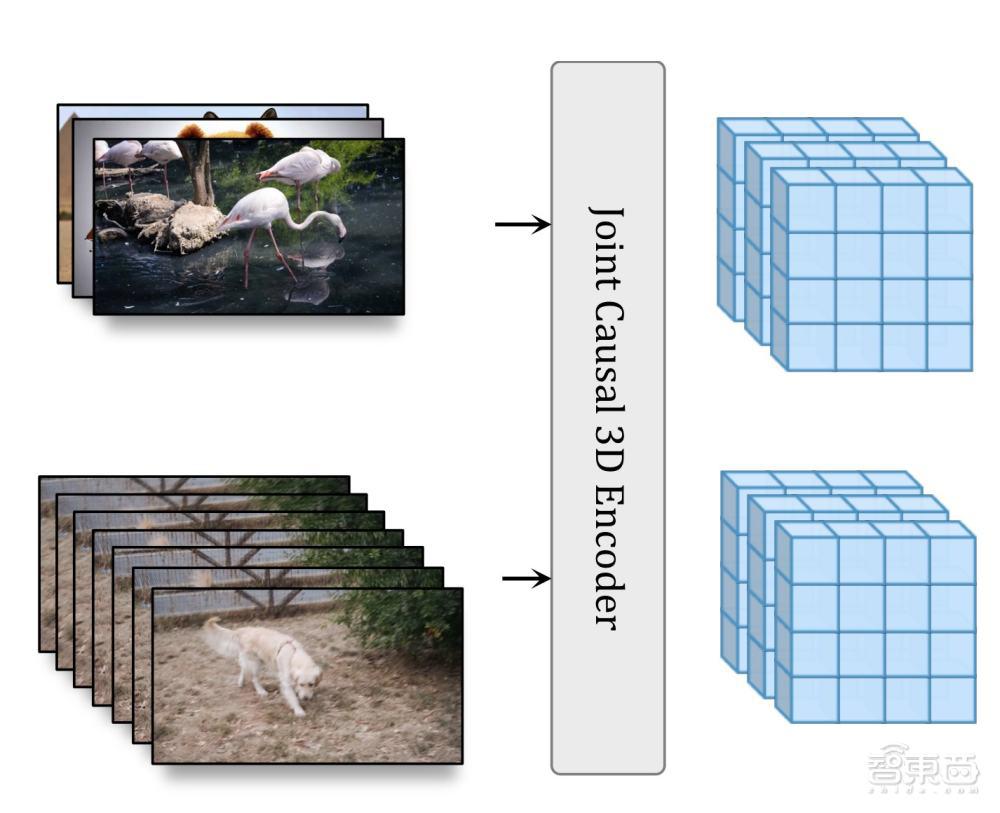
2、使用基于窗口注意力的 Transformer 架构,在潜在空间中联合时空生成建模,从而提高记忆和训练效率。
团队基于 W.A.L.T 训练了三个模型的级联(Cascade),用于文本到视频的生成任务,包括:一个基本的潜在视频扩散模型、两个视频超分辨率扩散模型。
在无需使用无分类器指导的情况下,W.A.L.T 在视频生成基准 UCF-101 和 Kinetics-600、图像生成基准 ImageNet 测试上实现了 SOTA。
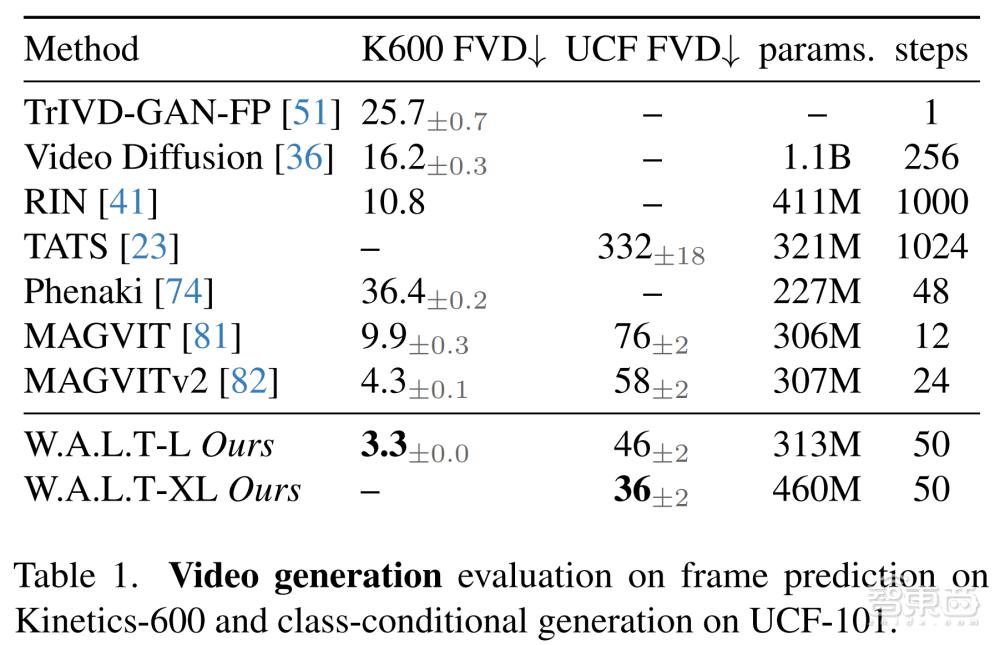
▲在基于 kinect-600 的帧预测和基于 UCF-101 的类条件生成的视频生成评价
三、AI 生成视频爆发,巨头和创企都加码了
短短一个月时间里,AI 生成视频赛道已成爆发态势,背后玩家不仅覆盖高校及科研团队,还有多家科技巨头及 AI 创企。
先是 11 月 3 日,视频生成领域的 " 老大哥 "Runway 宣布其 AI 视频生成工具 Gen-2 更新,分辨率提升至 4K,大幅提高保真度和一致性。一周后,Runway 又紧锣密鼓地发布了运动画笔功能,强化视频局部编辑能力。
Gen-2 体验地址:
https://research.runwayml.com/gen2
▲ Runway 在 X 平台宣布其 AI 视频生成工具 Gen-2 更新
紧接着,国内外的科技巨头都加入了这一赛道。
11 月 16 日,科技巨头 Meta 推出了文生视频模型 Emu Video。Emu Video 可以通过自然语言生成高质量视频,它将视频生成分为两个步骤,首先生成以文本为条件的图像,然后生成以文本和生成的图像为条件的视频。
项目主页地址:
emu-video.metademolab.com

11 月 18 日,国内大厂字节跳动推出了文生视频模型 PixelDance,提出了基于文本指导 + 首尾帧图片指导的视频生成方法,使得视频生成的动态性更强。
项目主页地址:
https://makepixelsdance.github.io

▲ PixelDance 的强动态效果演示
一些 AI 创企的做法则更激进,直接扔出体验体验链接,引爆消费级市场。
11 月 29 日,AI 创企 Pika Labs 推出网页版 Pika 1.0,一时间在消费级市场火出圈。Pika 1.0 能根据文字图片,生成一段 3s 的流畅视频;它还支持用户圈定视频里的元素,进行视频局部编辑。Pika 仅仅开放半年已有超 50 万用户,目前还有更多用户排队申请体验网页版 Pika 1.0 产品。Pika 是一家创立于今年 4 月的创企,近期刚刚宣布了 5500 万美元融资。
Pika 1.0 体验地址:
https://pika.art/waitlist
▲ Pika Labs 官宣网页版 Pika 1.0 上线
在图像领域深耕已久的 Stability AI 也不示弱。11 月 29 日,Stability AI 推出了名为 Stable Video Diffusion 的视频生成模型,提供 SVD 和 SVD-XT 两个模型。其中,SVD 将静止图像转换为 14 帧的 576 × 1024 视频,而 SVD-XT 在相同的架构下将帧数提升至 24。这两者都能以每秒 3 到 30 帧的速度生成视频,目前已进入 " 研究预览 " 阶段。
官方演示视频:
https://www.youtube.com/watch?v=G7mihAy691g
除此之外,国内美图公司发布的 AI 视觉大模型 MiracleVision 的 4.0 版本,刚刚新增了 AI 视频两大能力;来自中国科学院等机构的研究者在 11 月 21 日提出了一个无需训练的文本生成视频框架 GPT4Motion;阿里的研究团队在最新论文中提出了新框架 Animate Anyone,支持从静态图像 AI 生成动态视频。
商业化产品集中爆发,AI 生成视频技术似乎正迎来一个 "ChatGPT 时刻 "。
结语:技术和产品迭代扎堆,AI 视频生成赛道爆发
短短一个月时间里,我们看到 AI 视频生成的技术和产品加速爆发,科研机构、AI 创企和科技巨头都出动了。
仅仅一年之前,ChatGPT 以迅雷不及掩耳之势走向全球,为文本创作领域带来重大的变革,并掀起了全球范围内的 " 百模大战 "。
一年后的今天,AI 视频生成赛道或许迎来一个新的 "ChatGPT 时刻 ",国内外的玩家都已经 " 开卷 " 了,推动多模态大模型的升维竞赛打响。